1. Segmentation (세그멘테이션)
이미지를 작은 부분이나 세그먼트로 나누는 작업.
세그멘테이션의 두 가지 종류
- 시맨틱 세그멘테이션(Semantic Segmentation)
- 인스턴스 세그멘테이션(Instance Segmentation)
Semantic segmentation
이미지의 각 픽셀을 해당하는 객체 또는 클래스에 할당하는 작업
픽셀 수준에서 객체 또는 특정 패턴을 식별하는 것이 목표
(여기서 객체란 자동차, 사람, 동물 등)
Instance segmentation
각 객체 또는 인스턴스를 식별하고 픽셀 수준에서 분리하는 작업
동일한 클래스에 속하는 두 개 이상의 객체를 서로 다르게 식별할 수 있다.
ex) 여러 사람이 있는 이미지에서 각 사람을 따로 식별하고 구분

위 사진이 semantic segmentation과 instance segmentation의 차이를 잘 설명해준다.
1. 대상 단위의 차이
- semantic segmentation : 이미지를 여러 클래스로 나누어 각 픽셀에 해당하는 클래스 레이블을 할당
-> 한 이미지 내에서 동일한 클래스에 속하는 모든 픽셀은 동일한 레이블을 가진다. - instance segmentation : 이미지를 각 객체 또는 인스턴스로 나누어, 각 객체의 경계를 픽셀 수준에서 정확하게 식별
-> 여러 객체가 동일한 클래스에 속해 있더라도 서로 다른 인스턴스로 분리된다.
2. 목적의 차이
- sementic segmentation : 이미지 내의 전체 구조를 이해하고, 각 픽셀이 어떤 의미를 가지는지 파악하는 것
- instance sementation : 이미지 내에서 각 객체를 정확하게 분리하고 식별하여, 서로 다른 객체의 구분을 목표
3. 레이블링의 형태
- semantic segmentation : 픽셀 단위로 레이블을 할당하므로, 이미지 내의 모든 픽셀은 동일한 클래스 레이블을 공유
- instance segmentation : 각 객체에 대해 픽셀 수준의 고유한 레이블을 할당, 서로 다른 객체 간에 레이블이 다름
2. 이미지 분류 vs 이미지 세그멘테이션
이미지 분류 (Image Classification)
MNIST, CIFAR10, .. 등으로 실습한 이미지 분류는 주로 CNN 모델을 사용하게 된다.
CNN은 convolution layer를 가졌으며, loacl feature를 찾는데 유용하다.
CNN에서 하나의 kernel은 하나의 pattern을 학습하며,
sliding window하여 이미지 상에 해당 패턴이 어디에 얼만큼 나타나는 지를 계산하게 된다.

convolution으로 만들어진 feature map은 pooling layer와 FC layer를 통해 압축되며
최종적으로 이미지가 어떤 클래스(어떤 이미지)인지 global feature를 추론한다.
이미지 세그멘테이션 (Image Segmentation)
이미지 분류 문제를 푸는 동시에 localization 문제를 해결해야 한다.
localization : 이미지 내의 특정 물체 또는 객체가 어디에 위치하는지 찾아내는 작업

이미지 세그멘테이션은 CNN에서 구현한 이미지 분류처럼 convolution 연산을 활용한다.
하지만,
convolution layer의 pooling과 stride 연산을 거칠수록 spatial information이 사라진다는 문제점이 있다.
그리고, CNN과 같이 FC layer를 거치면서 이 spatial information이 모두 사라지게 된다.
그래서 1차 방안으로 FC layer가 convolution layer로 대체된다.
이는 FCN(Fully Convolution Network)라고 한다.
3. Image Segmentation - FCN
- Convolution layer : 지역적인 패턴이나 특징을 추출
합성곱 연산을 통해 특정 지역의 특징을 감지, 이러한 지역적인 정보들이 서로 겹쳐지면서 전체 이미지에 대한 특징을 학습하게 된다. - FC layer : 특정 위치의 특징과는 독립적으로 모든 입력과 연결되어 있는 구조
입력 데이터의 공간 구조를 고려하지 않고 모든 픽셀을 동일한 중요도로 취급한다.
FC layer를 여러 번 쌓게 되면, 공간적인 정보가 상대적으로 손실되는 경향
위 차이점으로 인해 FC layer를 Convolution layer로 바꾸었다.
segmentation을 위해서는 low-level, higher level, spatial information을 모두 학습해야한다.
- 저수준 특징 (low-level features)
- 낮은 수준의 추상화
- 데이터나 이미지의 세부적이로 구체적인 특성
- ex) 픽셀의 밝기, 색상, 가장자리 등과 같은 간단한 시각적 패턴 - 고수준 특징 (higher level features)
- 높은 수준의 추상화
- 데이터나 이미지의 전반적이고 추상적인 특징
- ex) 얼굴의 전체적인 윤곽이나 눈, 코, 입의 위치
그리고 spatial information을 보존하기 위한 방안으로,
- encoder-decoder 구조
- skip connection
이 두 가지가 제시된다.
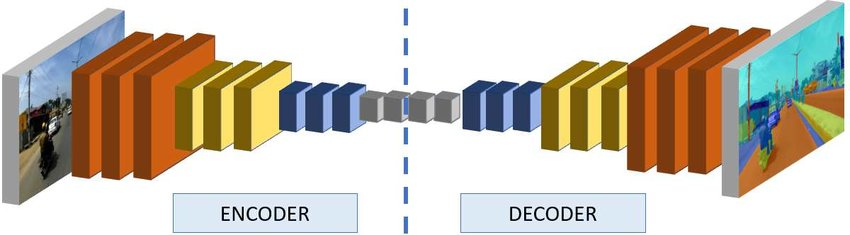
Encoder-Decoder
앞에서 언급했듯이,
pooling layer와 stride가 있는 convolution 연산은 공간 해상도를 줄이는 작업을 수행한다.
이 과정을 down sampling이라고 하는데, 이 다운 샘플링 과정은 이미지의 크기를 줄이며, 고수준 특징을 추출한다.
encoder가 이러한 down sampling을 수행하는 것이다.
encoder의 초기 layer에서는 저수준(low-level) 특징 추출
이후 layer에서는 고수준(high-level) 특징 추출을 수행한다.
decoder는 encoder에서 얻은 고수준 특징을 up sampling하여 입력 이미지의 원래 해상도로 복원시킨다.
이는 고수준 특징을 사용하여 세그멘테이션 맵을 생성하는 역할을 하게 된다.
Skip-connection
encoding 과정에서는 이미 spatial information 손실이 발생한다.이를 decoding한다고 해서 손실된 모든 정보가 회복되는 것은 아니다.
개별 pixel 하나 하나의 정보는 사라지기 때문.
그래서 segmentation의 공간적 정보 확보를 위해 skip connection을 사용한다.

skip connection은 신경망의 입력을 출력에 직접 추가하는 구조를 말한다.이는 신경망의 깊이가 깊어질 때 발생하는 gradient vanishing 문제 완화에 도움이 된다.
FCN에서 skip connection은네트워크의 중간 레이어에서 추출된 고수준(high-level) 특징을 더 낮은 레벨의 레이어에 직접 연결하는 구조이다.pooling 과정에서 손실된 공간적인 세부 정보를 복원하고, 세그멘테이션 작업에서 정확도를 향상시키는데 도움을 준다.
4. Deep learning
Fully Convolution Networks (FCN)
U-Net (FCN 강화 모델)
DeepLab
Mask R-CNN
위 딥러닝 기술들을 사용해 효과적으로 이미지 세그멘테이션을 구현해낸다.
이 다음 글에서, U-Net의 구조와 함께 세그멘테이션 원리에 대해 더 자세히 알아보도록 하겠다.
'Deep Learning' 카테고리의 다른 글
| VAE(Variational Auto-Encoder) (0) | 2024.11.03 |
|---|---|
| Cycle GAN (0) | 2024.10.11 |
| Conditional GAN (0) | 2024.10.11 |
| GAN (Generative Adversarial Network) (2) | 2024.03.24 |
| U-Net : Image segmentation | U-Net 구조 이해하기 (0) | 2024.02.04 |