1. GAN이란?
GAN은 Generative Adversarial Network
즉, 적대적 생성 신경망으로, 2014년 Ian Goodfellow가 발명한 비지도 학습 알고리즘이다.
GAN은 두 개의 Neural Network인 Generator와 Discriminator로 구성되며
이 두 신경망이 서로 경쟁하며 학습하는 구조를 가진다.
2. Generative model
분류 모델은 decision boundary를 학습하며 sample x가 주어졌을 때 label y의 확률 P(y|x)를 추정
생성 모델은 각각의 class에 대해 적절한 분포를 학습하며, sample x의 확률분포 P(x)를 추정
이미지 데이터셋을 예로 들면, 이미지의 다양한 특징을 반영한 특정 확률 분포가 존재하며
확률값이 높은 부분은 해당 이미지의 특징을 많이 내포하게 된다.

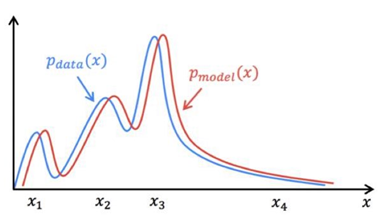
그렇기 때문에 생성 모델은 이 분포를 잘 학습한다면, 새로운 Data를 생성해낼 수 있으며
높은 확률값을 가지는 부분에서 적절한 노이즈를 추가하여 가짜 이미지를 생성하여 실제 이미지와 유사한 형태를 갖도록 한다.
3. GAN의 구조
위에서도 언급했듯이, GAN은 2가지 신경망, 생성자와 판별자로 구성된다.
- Generator(생성자) : random한 노이즈로부터 실제와 같은 데이터를 생성 (생성 모델)
- Discriminator(판별자) : 생성된 데이터가 실제 데이터인지, 생성자에 의해 만들어진 fake 데이터인지 판별 (분류 모델)

latent vector
생성자는 latent vector를 입력으로 받아 fake data를 만들게 된다.
이 벡터는 일반적으로 균등 분포나 정규 분포 등의 확률 분포에서 무작위로 샘플링되며,
가짜 데이터를 생성하는 데 사용되는 공간의 표현이다.
GAN의 학습 과정에서,
생성자는 latent vector를 입력으로 받아 실제 데이터와 유사한 가짜 데이터를 생성하려고 노력하게 된다.
4. Discriminator의 학습
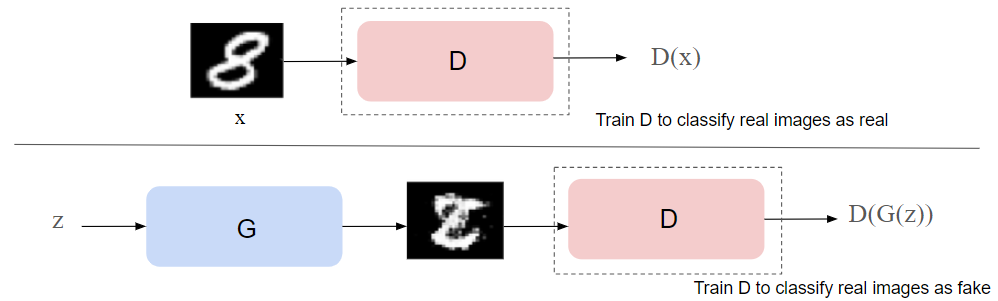
GAN의 학습 과정은 Discriminator, 즉 판별자의 학습부터 시작한다.

- 실제 데이터와 판별자가 생성한 가짜 데이터를 사용하여 판별자를 학습
- 실제 데이터를 real(1), 가짜 데이터를 fake(0)로 분류하도록 학습됨
input : 이미지의 고정된 고차원 벡터
output : 0 or 1 판별
x : 입력 데이터 (원본 데이터)
z : latent vector
D(x) : Discriminator의 판별
G(z) : Generator가 만든 가짜 데이터
Discriminator는 D(x) 1(real), D(G(z))는 0으로 판별하도록 학습
5. Generator의 학습
Discriminator를 먼저 학습시키는 이유 중 하나는
처음에 Generator를 먼저 학습시키면, Discriminator가 가짜 데이터를 쉽게 식별할 수 있어 생성자가 아무런 도움 없이도 이미 좋은 결과를 얻어 버린다.
-> Generator와 Discriminator 간의 균형이 깨져서 학습이 잘 이루어지지 않을 수 있다.

Genrator는 Discriminator가 fake data를 1(real)로 판별하도록 학습한다.
즉, Discriminator가 fake data를 진짜로 생각하도록 만든다는 것이다.
Generator의 feed forward : noise(z)를 받아서 fake data로 만들기 -> Discriminator에 넣기 -> D(G(z))가 1이 되도록 학습
6. Objective function(loss function) - Discriminator 관점
GAN의 Objective function은 minmax problem 형태이다.
GAN의 최종적 목표는 생성자와 판별자 간의 균형을 유지하면서도 생성자가 실제 데이터와 거의 구별할 수 없는 고품질의 데이터를 만들어내는 것이다. 이를 위해 minmax problem으로 풀 수 있으며,
생성자는생성된 데이터가 판별자에 의해 최소화되는 것을 원하고, 판별자를 이를 최대화하여 서로를 이기도록 학습한다.
(Genrator와 Discriminator간의 loss fucntion)
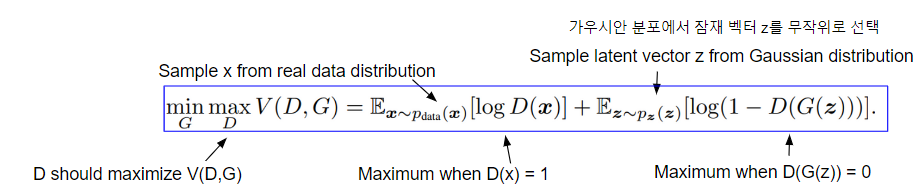
첫 번째 항은 real data의 확률 분포이며, 두 번째 항은 fake data에 대한 확률 분포가 되겠다.
Discriminator의 관점에서는, 가짜와 진짜를 분명하게 판별해내야하기 때문에 loss function이 maximize되도록 해야한다.
그렇기 때문에 D(x)가 1일 때 최대, D(G(z))가 0일 때 최대를 가지므로,
이에 맞게 D(x)를 1로 판별하도록, D(G(z))를 0으로 판별하도록 학습하는 것이다.
6. Objective function(loss function) - Generator 관점

똑같은 수식이지만, Generator는 첫 번째 항에 관여하지 않는다.
생성자 입장에서는 판별자가 가짜 이미지에 대해서도 "진짜"라고 판별하도록 해야하므로
위 수식이 minimize되도록 학습하게 된다.
그렇게 때문에 D(G(z))가 1이 될 때 log(1-D(G(z))가 최소화되므로 D(G(z))가 1이 되도록 학습하게 된다.

7. Objective function의 한계
6번에서 언급한 Generator의 loss function은 실제로 저렇게 구현되지 않는다.

이론상 이와 같은 수식으로 구현되는 것이 맞지만

GAN의 학습 초반, Generator는 당연히 어색한 이미지를 생성하게 되며,
Discrimiantor는 이를 당연히 가짜 이미지라고 쉽게 판별할 수 있다.
이렇게 판별자가 가짜로 판별하고 있는 상태(판별자의 출력값이 0에 매우 가까운 작은 값)가 되며
생성자의 gradient는 상대적을 작기 때문에 생성자의 학습이 제대로 이루어지기 어렵다.


이에 대한 해결책으로 log(1-x)를 최소화하는 것이 아닌, log(x)를 최대화하는 방식으로 구현된다.
이렇게 되면 상대적으로 큰 gradient를 가지게 되며,
학습 초반 Generator가 매우 안 좋은 상황을 최대한 빠르게 벗어날 수 있게 된다.
8. MNIST 구현 - MLP


Discriminator
input size : 784 (28x28)
output size : 1 (binary classification)
Generator
input size : 100 (100차원 latent vector)
output size : 784

학습 과정인 위와 같이 구성하였으며
BCD Loss를 사용한다.
여기서 Back propagation을 자세히 살펴보자.
9. Network Back propagation

Generator의 가중치를 업데이트 시키려면 Discriminator에서부터 back propagation 시켜야한다.
이는 결국 Discriminator의 가중치를 가져와서 학습하게 되는 것이다.
Generator는 Discriminator의 피드백을 통해 자신의 성능을 향상시키고
Discriminator는 피드백을 통해 자신의 성능을 향상시키는 것이 아니라,
생성된 데이터와 실제 데이터를 구별하는 데 더 잘 수행할 수 있도록 자신의 가중치를 조정한다.
10. DCGAN
마지막으로 DCGAN에 대해 간략하게 알아보자.

DCGAN은 Deep Convolutional GAN의 약자로,
GAN의 모델 구조에 Convolution을 사용한다는 것이 차이점이다.
- Discriminator
CNN - Generator
- deep convolutional NN
- deconvolution, transpose convolution -> upsampling - No pooling layer
high level, low resolution feature를 사용하는 classification과 다르게 실제로 이미지를 생성해야하기 때문에
filter로 작용되는 pooling layer를 사용하지 않음 (정보 손실 방지) - Generator의 입력인 latent vector z간의 산술적 연산이 가능(선형적 관계)
DCGAN latent vector arithmetic
DCGAN 특징 중 마지막에 언급했던 latent vector간의 산술적 연산이 가능하다는 것은

왼쪽 사진과 같이 이미지 데이터를 예시로,
안경 쓴 남자의 특징이 담긴 latent vector에서
남자의 특징이 담긴 이미지를 뺄셈 연산을 하면
"안경" 특징이 담긴 이미지가 생성됨
이를 안경을 안 쓴 여성의 latent vector와 덧셈 연산을 수행하면 안경 쓴 여성의 특징이 담긴 이미지가 생성됨
MNIST dataset을 사용하여 학습하게 되면
MLP 구조의 GAN보다 DCGAN이 더 명확하게 가짜 이미지를 만들어낸다.

'Deep Learning' 카테고리의 다른 글
| VAE(Variational Auto-Encoder) (0) | 2024.11.03 |
|---|---|
| Cycle GAN (0) | 2024.10.11 |
| Conditional GAN (0) | 2024.10.11 |
| U-Net : Image segmentation | U-Net 구조 이해하기 (0) | 2024.02.04 |
| [Deep learning] Image Segmentation (0) | 2024.02.04 |